Django for Data Science @ Boston Python Meetup
On Tuesday I presented a talk to the Boston Python Meetup titled “Django for Data Science: Deploying Machine Learning Models with Django”. It’s a version of an upcoming keynote I’ll be giving at DjangoCon Europe in Dublin, Ireland next month.
Initially, this presentation was intended as a 25 minute technical talk answering a question I’ve long had: How easy/difficult is it to combine data science and the web? These two communities are the dominant ones within the current Python ecosystem and yet it is rare that a developer can work fluently in both.
Most web developers, like me, know little about how to build, train, and deploy Machine Learning models. And most ML engineers are clueless about the web. Granted, “data science” means far more than just machine learning, but I had to narrow the focus somewhat.
I’m pleased to report that the short answer is, It’s quite doable! In fact, during the talk I show exactly how little code it takes to do it.
Slide Deck and Repos
Here is the slide deck if you’re curious (this will be updated before my DjangoCon keynote):
Step one is to create a new Jupyter notebook, install pandas, scikit_learn, and joblib, and then train a model. For the talk, we use the class Iris dataset. You can see the entire code in this GitHub repo if you’re curious.
One of the key insights is that we can store our model as a joblib file that can then be imported into a Django web application. The second half of the talk shows how to build the Django side of things, which you can see in this repo.
DjangoforDataScience.com
And the moment I’m most proud of in the talk is when I direct viewers to a live website, DjangoforDataScience.com [note: no longer live], where they can try out what we’ve built.
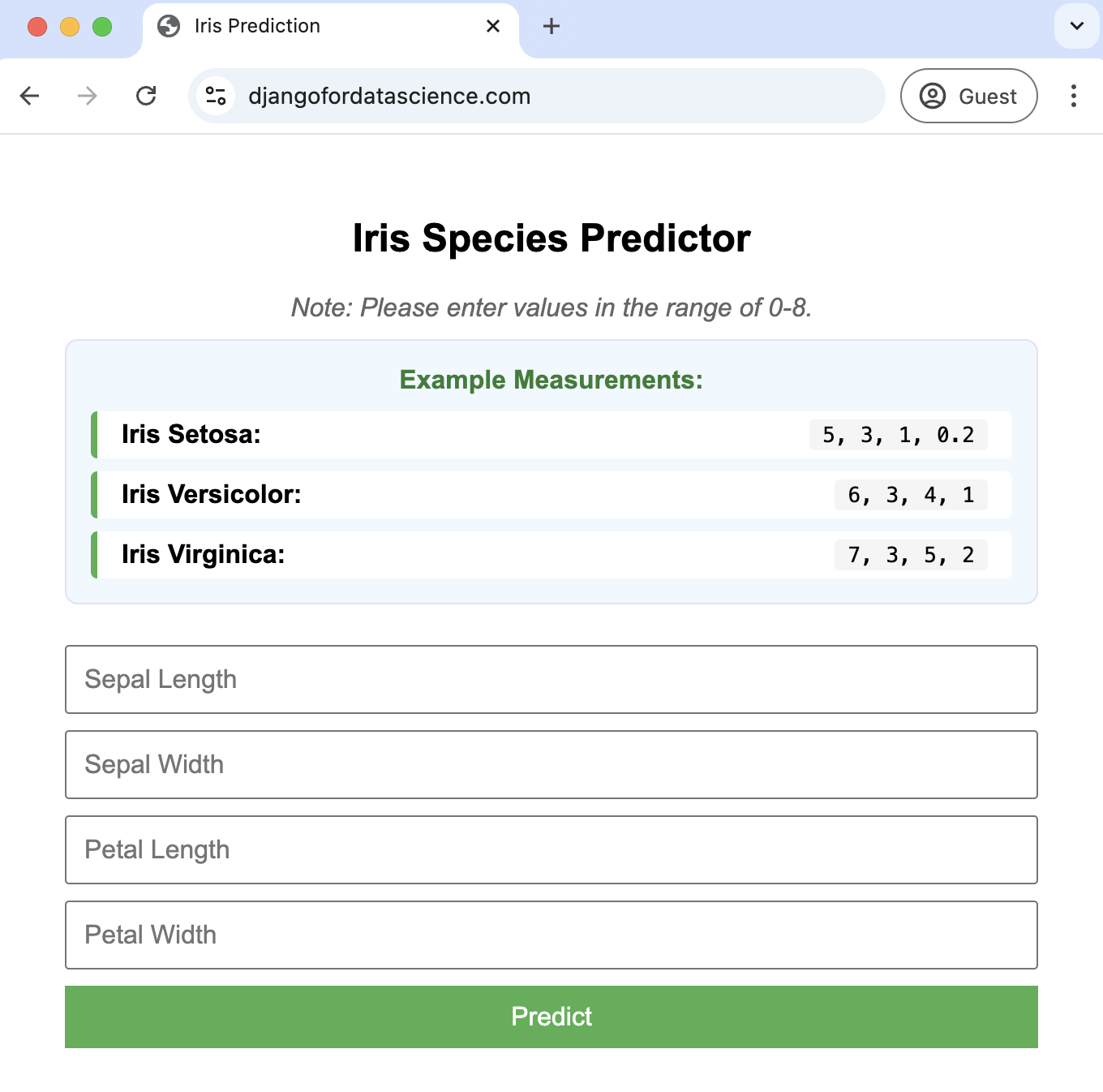
While doing this live I log into the Django admin view and can show how all the user inputs and model predictions are stored within a database, updated in real-time.
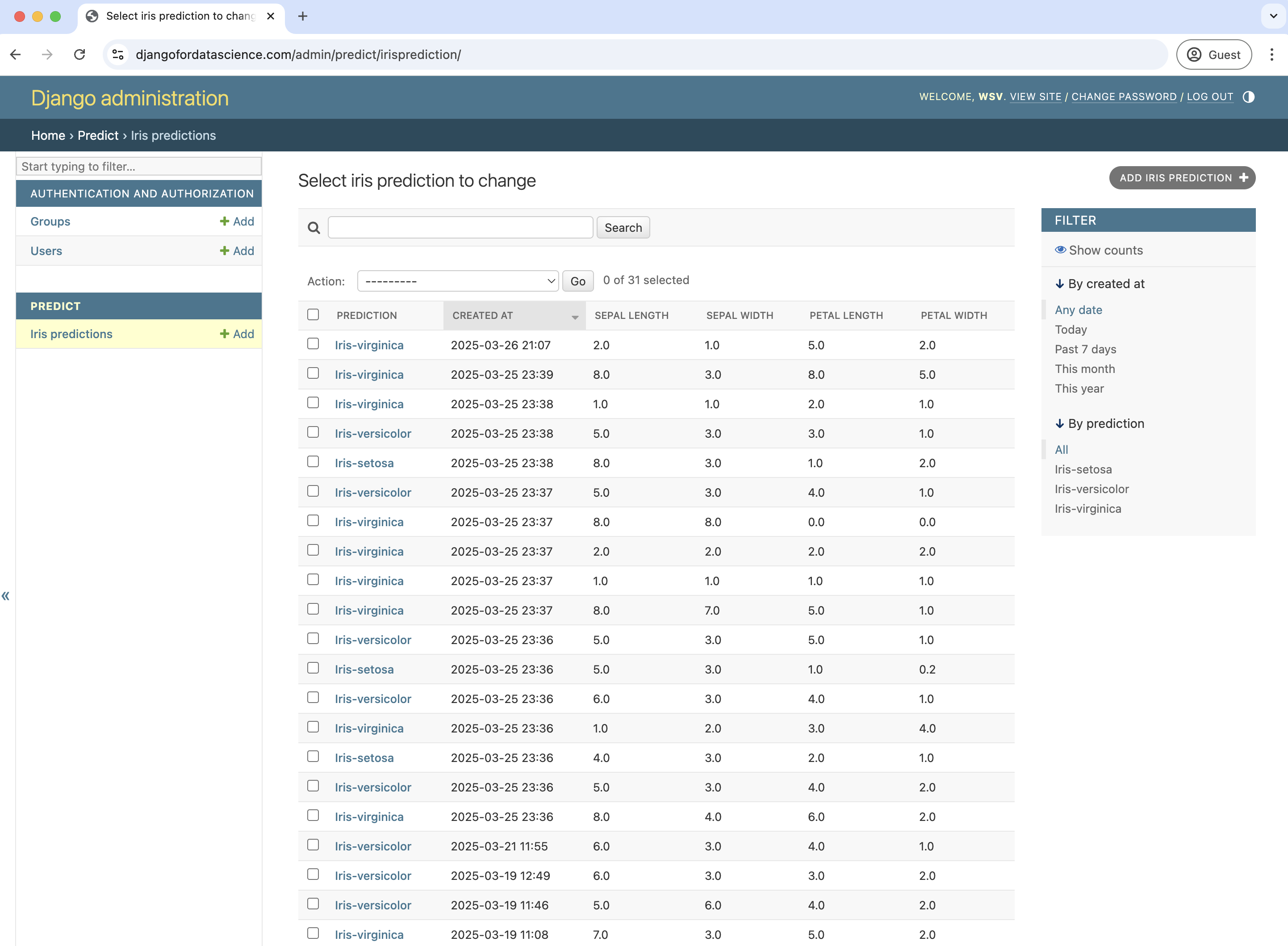
In the real world, a ML engineer would want to try out multiple models, incorporate user results into re-training the model, and so on. But this works as a good demonstration of how to do it in a simplified manner.
Updates for Next Time
As ever when giving a talk, my mind thinks of how to do it better the next time. And fortunately, in this case, I have a month to do so. Here’s what I’m thinking at the moment:
- More on ML, using different algorithms, and datasets for training.
- More context on data science in general.
- Less just talking through code. I’m proud of the repos but hearing me go line-by-line for more than a few minutes is tough to make engaging.
- Move the live website demo into the middle of the talk rather than the end. It’s a lot to do the ML section. Switching to the live demo is a good change of pace. And then we’ll go into the Django bits.
- More on deployment? I have slides showing how it took me ~10 minutes to deploy a Django website, but that’s me with years of experience and a detailed checklist. I suspect this is best left as a future DjangoCon talk subject.
PyCharm Things
A final note is I had a lot of discussions around PyCharm and text editors/IDEs in general. At the moment, I’m working on all the materials related to the April launch of PyCharm 2025.1. There’s a lot of cool stuff. But I realized talking to people that most developers want the very cliff notes version of it since they’re busy doing other things.
Internally, we have a list of 20 odd things related to the launch that we’re excited about. But I think the short version is this:
- PyCharm AI is coming that will let you use LLMs within the IDE. Check out this short video for a demo.
- We have our own agent, Junie, that is launching soon and is super cool. Be on the lookout for demos related to this.
- PyCharm 2025.1 will be one single install, rather than separate Community and Professional editions.