How The Web Works
The World Wide Web (the Web) is a collection of webpages found on the Internet. It was created in 1989 by Tim Berners-Lee, a scientist, who wanted an easier way to share data from experiments with his peers.
While the Internet, a worldwide network of connected computers, had existed in various forms since the 1960s (see How Does the Internet Work?), its use was largely confined to military and academic settings. The Web was different: it made the Internet accessible to everyone and allowed people create and share work through websites, blogs, video sharing, and more.

If you want to connect with another computer to, for example, visit a webpage, you need to know that computer’s address. Any device connected to the Internet has an IP address (Internet Protocol), which is uniquely identifying series of numbers.
Note: To find the IP address of your computer or phone type “What is my IP address?” into Google.com.
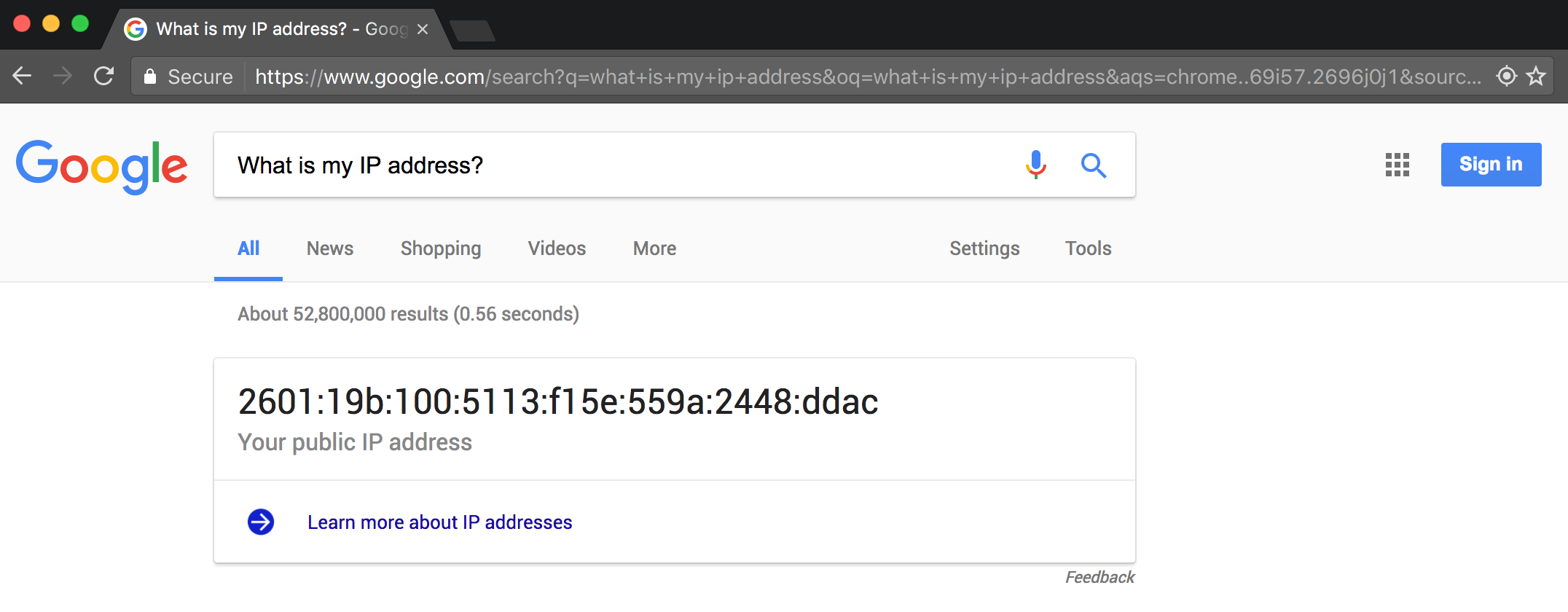
Any time you visit a webpage such as Google.com behind the scenes you are really visiting an IP address. For example, try typing 216.58.217.78 into your web browser (Chrome/Safari/Firefox/etc) and hit Enter.
What happened? You typed in an IP Address but ended up at Google.com! The phrase Google.com is formally known as a URL (Uniform Resource Locator) and is how humans navigate the Web; it’s far too hard to remember IP addresses! The machines that translate URLs into IP addresses are called Domain Name Servers. Their job is to translate URLs which are human-readable into IP addresses which are computer-readable.
Servers
The computers powering the internet are often referred to as servers. They’re just computers connected to the Internet all the time that are running special software that lets them “serve” information to other computers. Your own computer can be a server, but in practice servers exist in large data centers.

When you hit Return on a URL you are making a request for information. Somewhere on the internet, a server is “serving” you a response that causes your web page to load.
Further Down the Rabbit Hole
In practice, a request for a server often has to be routed through various servers until it reaches its final destination. There’s a cool tool, traceroute, that lets us see this first hand. To run it yourself, open the Terminal application (on a Mac) or Command Prompt (if on Windows). Type traceroute <URL> where "<URL>" stands for the URL you want to see.
For example, here’s what I get in Boston, MA from typing traceroute Google.com.
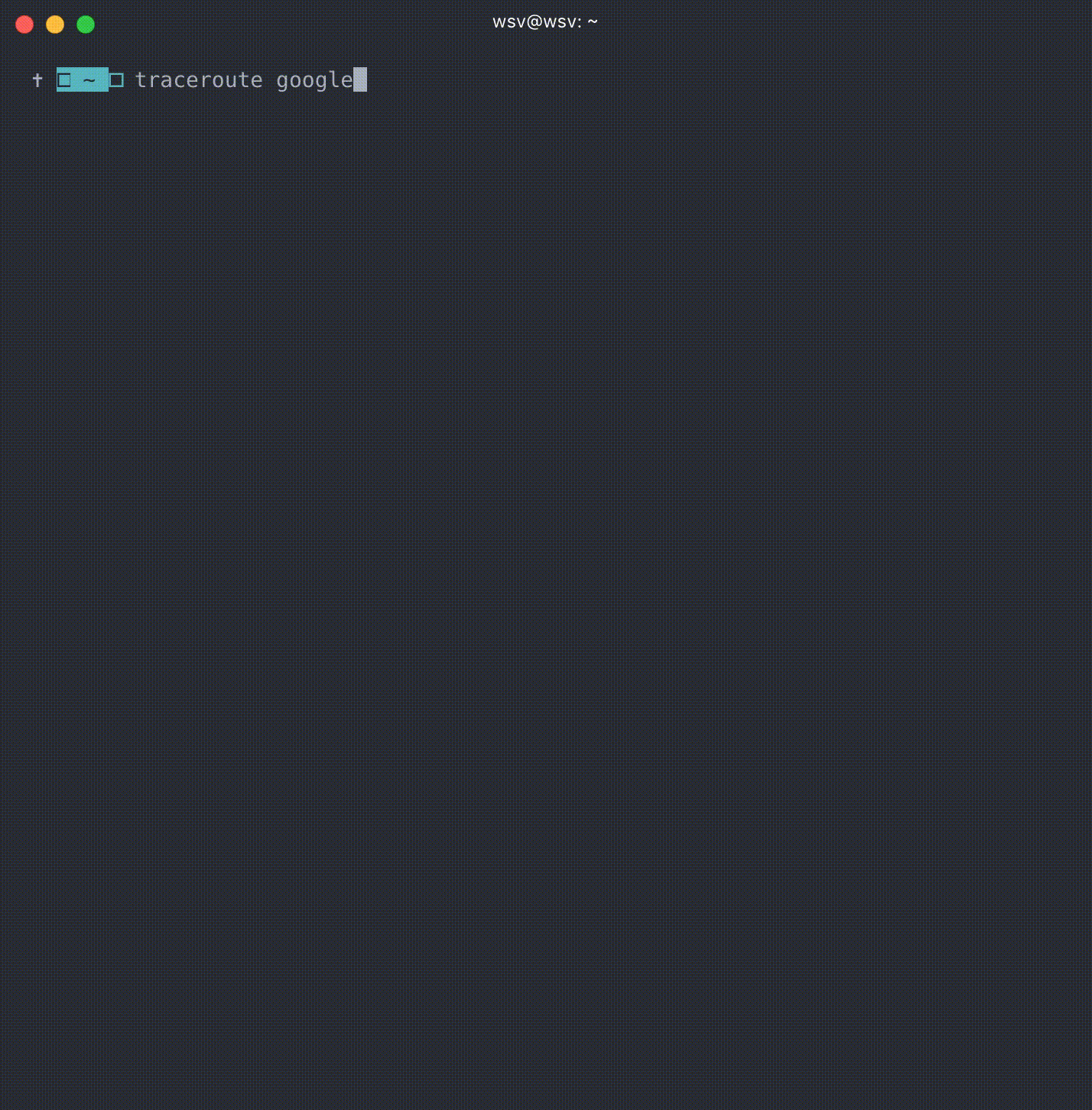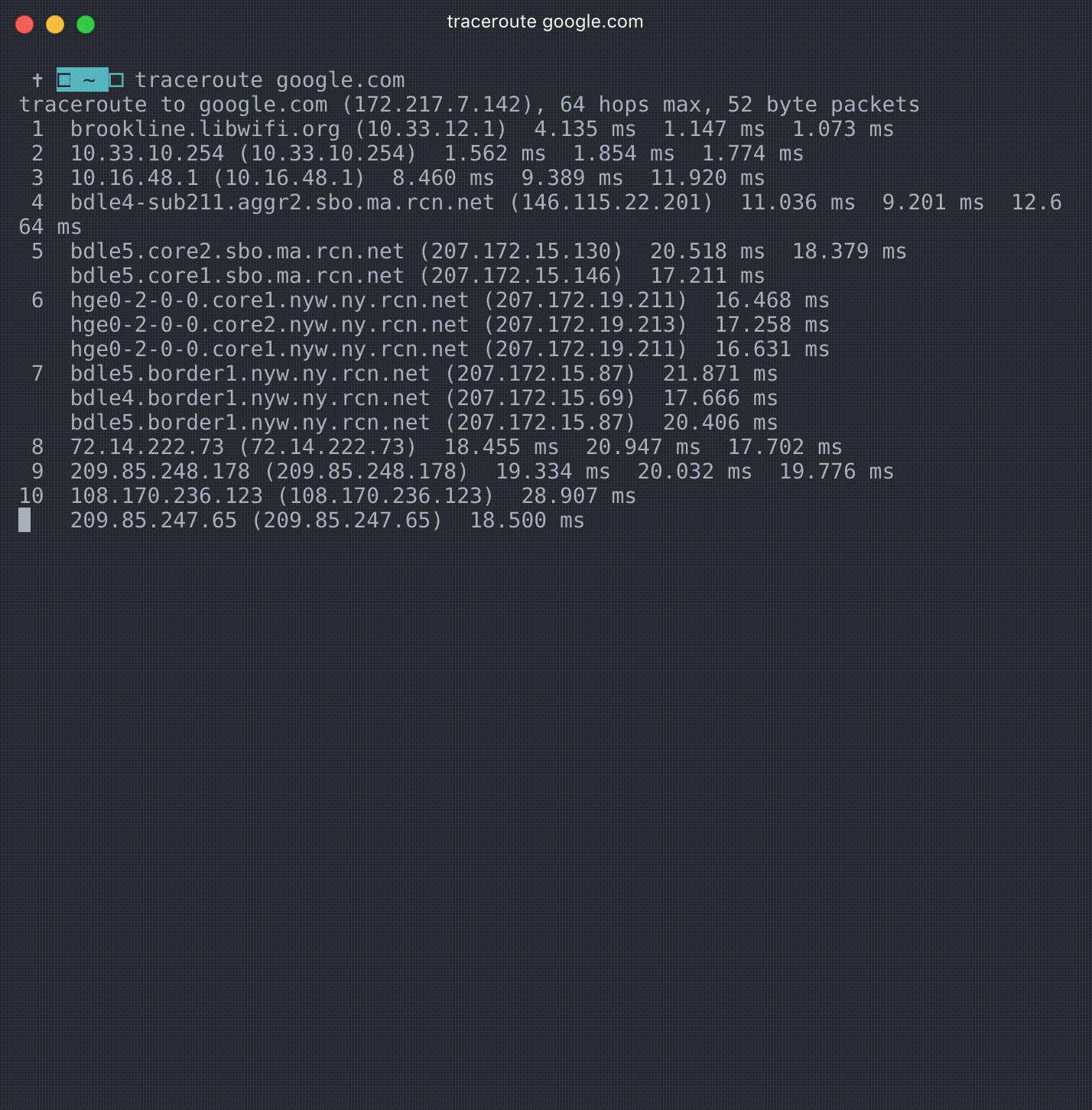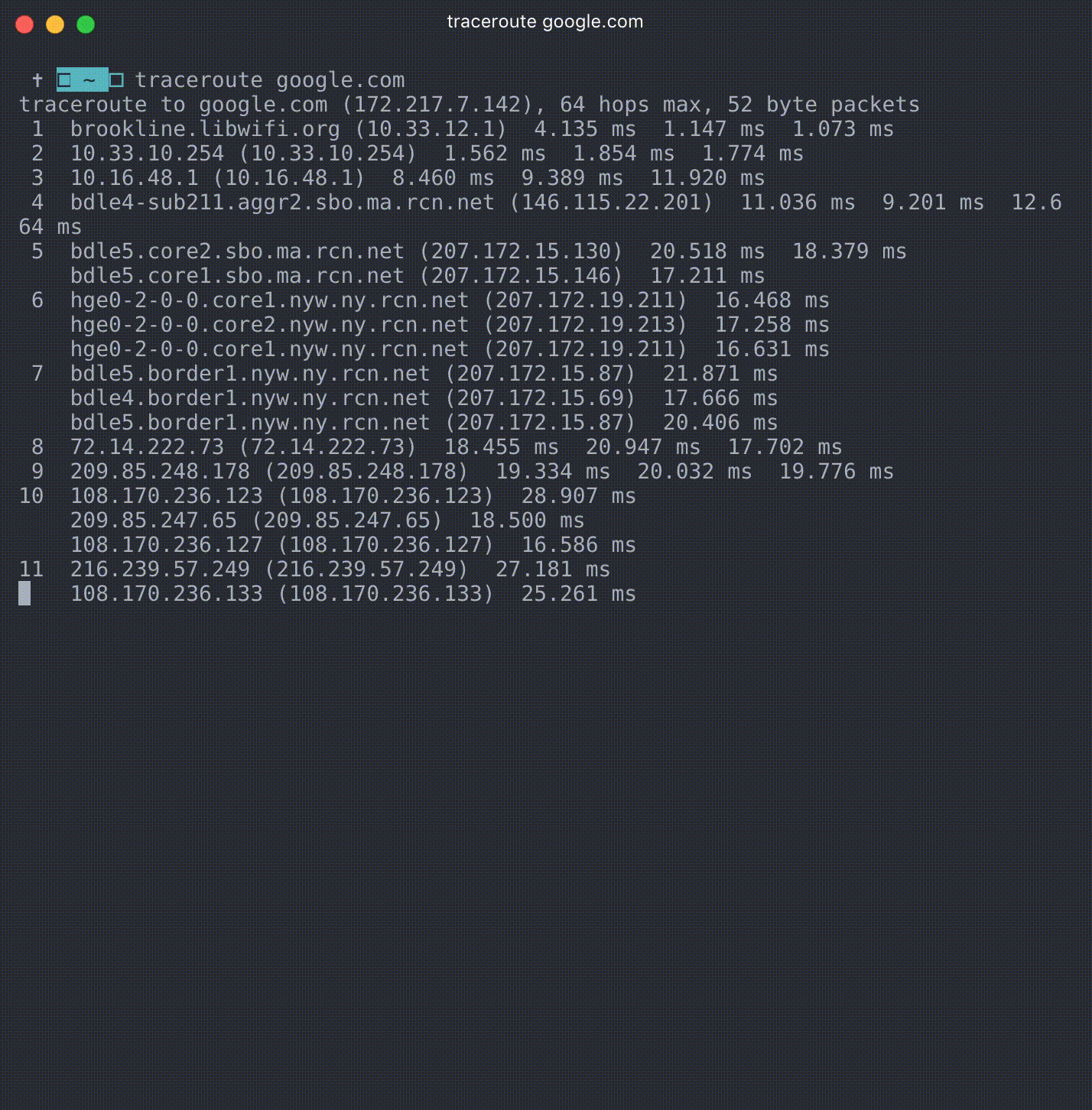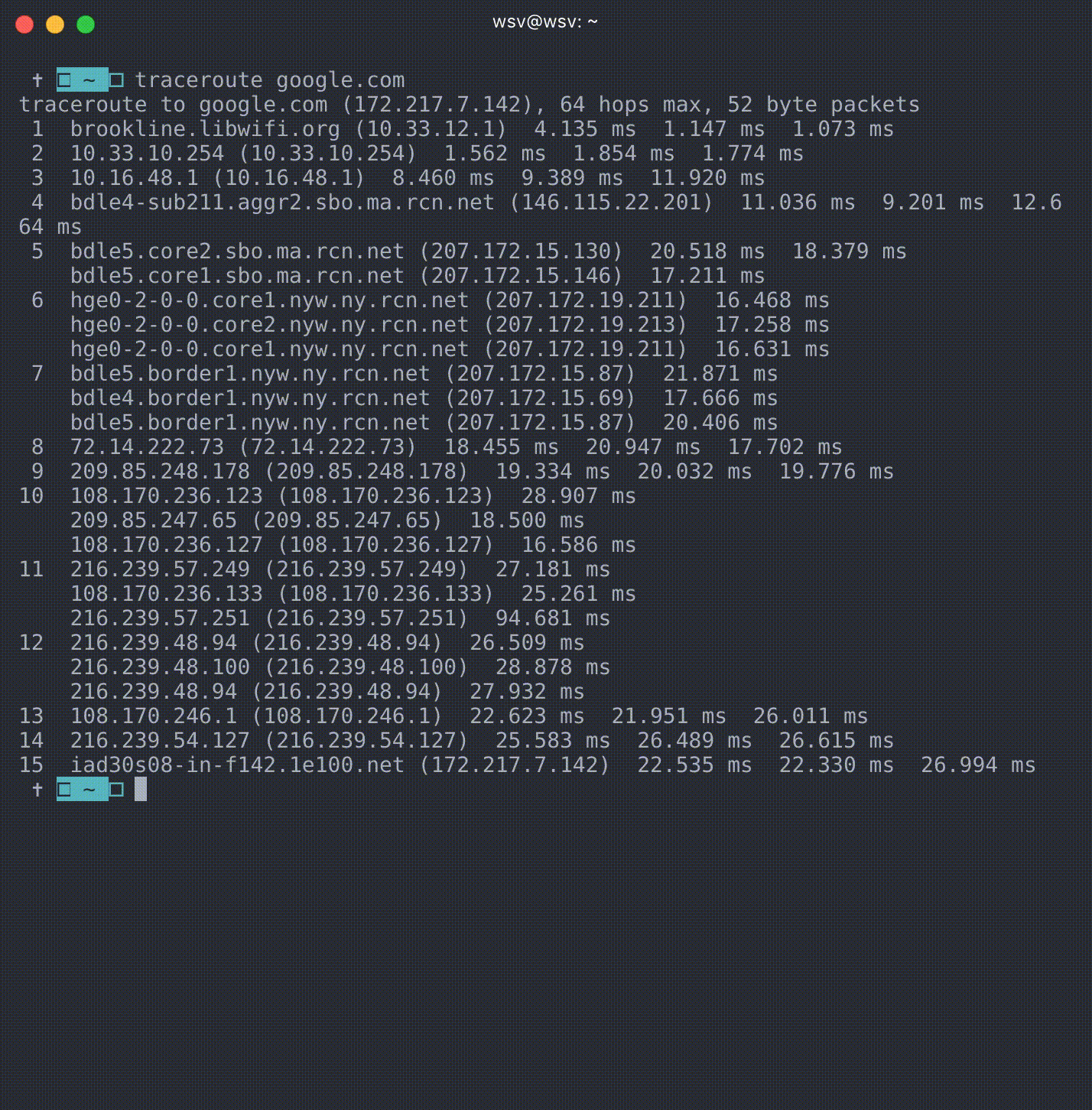
What’s literally happening here is the Internet at work! You can see on line 1 I’m actually at the Brookline Public Library wifi. From there I’m bounced around from server to server–on line 6 I’ve moved out of Massachusetts and into NYC–until finally on line 15 (it takes 15 different servers!) before I’m connected with one that sends me information for Google.com.
Pretty cool, huh? If you try this out yourself, you’re guaranteed to see different results. Also note that this wasn’t instantaneous. This is why, in practice, a large company like Google has server farms all over the world so that it can serve web pages and results as fast as possible.